Develop a new agent (for your simulation)¶
In the previous tutorial, we implemented a world simulation called
TripsWorld in which agents negotiated how to spend their holiday
seasons. In this tutorial we will develop agents for this world and take
it on a test-drive.
Making a Random Agent for the Trips World¶
Our random agent, will just use a random negotiator for everything and will not keep track of the history of other agents. That is the complete code which is self explanatory this time.
class RandomPerson(Person):
def step(self):
# get IDs of all ogher agents from the AWI
agents = self.awi.agents
# request the maximum number of negotiations possible
for _ in range(self.awi.n_negs):
# for each negotiation, use a random subset of partners and a random negotiator
self.awi.request_negotiation(
partners=sample(agents, k=randint(1, len(agents) - 1)),
negotiator=RandomNegotiator(),
)
def init(self):
# we need no initialization
pass
def respond_to_negotiation_request(
self,
initiator: str,
partners: List[str],
mechanism: NegotiatorMechanismInterface,
) -> Optional[Negotiator]:
# just us a random negotiator for everything
return RandomNegotiator()
Testing the world¶
We can now start world simulations using our new world and agent
world = TripsWorld(n_steps=_N_STEPS_SHORT, construct_graphs=True)
for i in range(5):
world.join(RandomPerson(name=f"a{i}"))
world.run_with_progress()
Output()
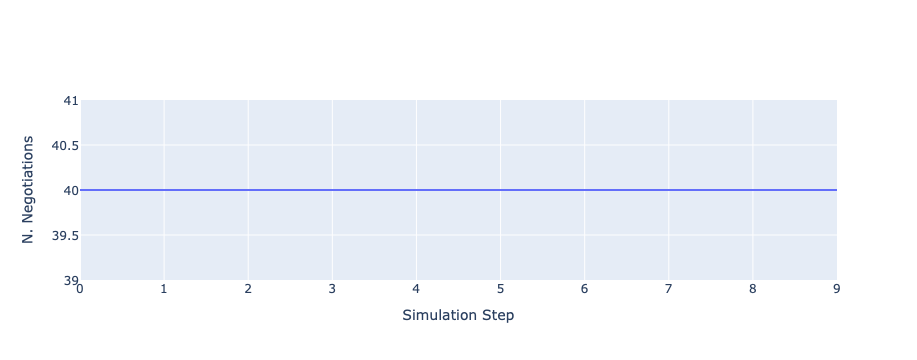
Let’s see what happened in this run. Firstly, how many negotiations were conducted over time. Our agents always conducted the maximum number of negotiations (\(8\)) and we had \(5\) agents which means we expect \(40\) negotiations at every step.
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(y=world.stats["n_negotiations"], mode="lines"))
fig.update_layout(xaxis_title="Simulation Step", yaxis_title="N. Negotiations")
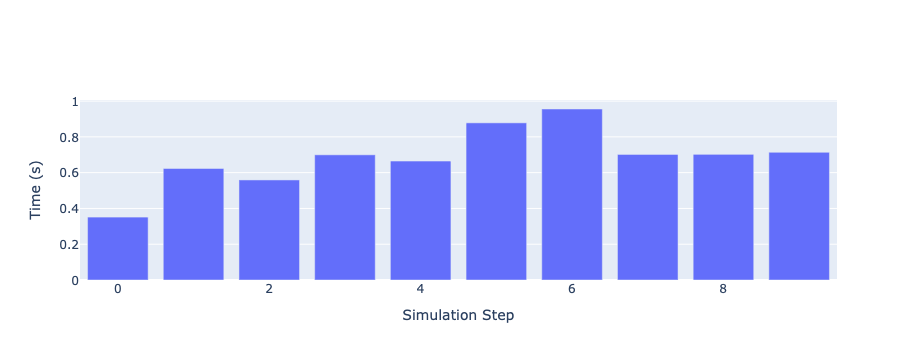
Let’s start by seeing how long did each step take (note that stats access the stats as a Dict[str, List] but stats_df access the same data as a pandas dataframe.
def stats_df(world):
return pd.DataFrame(world.stats)
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Bar(x=list(range(world.n_steps)), y=stats_df(world)["step_time"]))
fig.update_layout(xaxis_title="Simulation Step", yaxis_title="Time (s)")
We can for example check the welfare (activity level) of this world (defined as the total contract sizes executed per step which in our case correspond to the total welfare)
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(y=world.stats["activity_level"], mode="lines"))
fig.update_layout(
xaxis_title="Simulation Step", yaxis_title="Activity Level ($)\nTotal Welfare"
)
fig

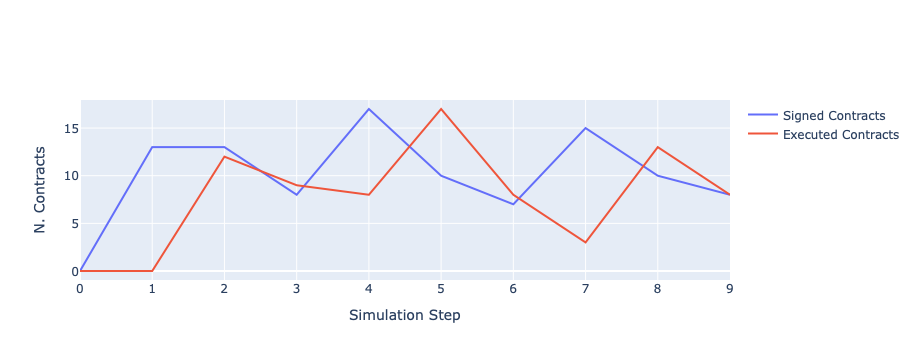
We can see a picture of contracting in this world as follows:
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Scatter(
y=world.stats["n_contracts_signed"], mode="lines", name="Signed Contracts"
)
)
fig.add_trace(
go.Scatter(
y=world.stats["n_contracts_executed"], mode="lines", name="Executed Contracts"
)
)
fig.update_layout(xaxis_title="Simulation Step", yaxis_title="N. Contracts")
We can also check the breaches that happened
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(y=world.stats["breach_level"], mode="lines"))
fig.update_layout(xaxis_title="Simulation Step", yaxis_title="Total Breach Level")
We can actually check what happens to ALL agents
import plotly.graph_objects as go
fig = go.Figure()
snames = sorted(_.name for _ in world.agents.values())
for name in snames:
fig.add_trace(
go.Scatter(
y=np.asarray(world.stats[f"total_utility_{name}"]), mode="lines", name=name
)
)
fig.update_layout(
xaxis_title="Simulation Step",
yaxis_title="Player Total Utility",
legend=dict(x=0, y=0),
)
fig

As you can see, the total utility is not monotonically increasing. This
means that agents accepted offers that have a utility less than their
reserved value. That is expected because we use RandomNegotiators
for all negotiations.
We can also get a graphical view of all activities during the simulation:
world.draw(steps=(0, world.n_steps), together=False, ncols=2, figsize=(20, 20))

(None,
[<networkx.classes.digraph.DiGraph at 0x1168f3b60>,
<networkx.classes.digraph.DiGraph at 0x116490550>,
<networkx.classes.digraph.DiGraph at 0x11697df90>,
<networkx.classes.digraph.DiGraph at 0x116a1c050>,
<networkx.classes.digraph.DiGraph at 0x116a1c180>,
<networkx.classes.digraph.DiGraph at 0x11696fbf0>,
<networkx.classes.digraph.DiGraph at 0x1169ea140>,
<networkx.classes.digraph.DiGraph at 0x1169ea250>,
<networkx.classes.digraph.DiGraph at 0x11699e550>,
<networkx.classes.digraph.DiGraph at 0x11699e750>])
Making a Better Agent for the Trips World¶
As we have seen, the random agent did not behave well in this world. It is pretty simple to extend it into a better agent. Here is a simple attempt:
class SanePerson(Person):
"""An agent that uses a predefined negotiator instead of a random negotiator"""
def __init__(
self,
*args,
negotiator_type=AspirationNegotiator,
negotiator_params=None,
**kwargs,
):
super().__init__(*args, **kwargs)
self.negotiator_type = negotiator_type
self.negotiator_params = (
negotiator_params if negotiator_params is not None else dict()
)
def step(self):
# get IDs of all ogher agents from the AWI
agents = self.awi.agents
# request the maximum number of negotiations possible
for _ in range(self.awi.n_negs):
# for each negotiation, use a random subset of partners and a random negotiator
self.awi.request_negotiation(
partners=sample(agents, k=randint(1, 2)),
negotiator=self.negotiator_type(
ufun=self.ufun, **self.negotiator_params
),
)
def init(self):
pass
def respond_to_negotiation_request(
self, initiator: str, partners: List[str], mechanism
) -> Optional[Negotiator]:
# just us a random negotiator for everything
return self.negotiator_type(ufun=self.ufun, **self.negotiator_params)
The only difference between this SanePerson and the RandomPerson
we developed earlier is that it can be constructed to use any type of
negotiation strategy supported in NegMAS (i.e. any SAONegotiator
class). Whenever it is asked for a negotiator (either in step or
respond_to_negotiation_request) it uses that negotiator setting its
utility function.
Let’s try it
world = TripsWorld(n_steps=_N_STEPS_LONG, construct_graphs=True)
for i in range(3):
world.join(RandomPerson(name=f"rand-{i}"))
for i in range(3):
world.join(SanePerson(name=f"sane-{i}"))
world.run_with_progress()
Output()
Let’s check how did our agent do
import plotly.graph_objects as go
fig = go.Figure()
snames = sorted(_.name for _ in world.agents.values())
utils = dict(sane=np.zeros(world.n_steps), rand=np.zeros(world.n_steps))
for agent_name in (_.name for _ in world.agents.values()):
utils[agent_name.split("-")[0]] += np.asarray(
world.stats[f"total_utility_{agent_name}"]
)
for name in utils.keys():
fig.add_trace(go.Scatter(y=utils[name], mode="lines", name=name))
fig.update_layout(
xaxis_title="Simulation Step",
yaxis_title="Player Total Utility",
legend=dict(x=0, y=0),
)
fig
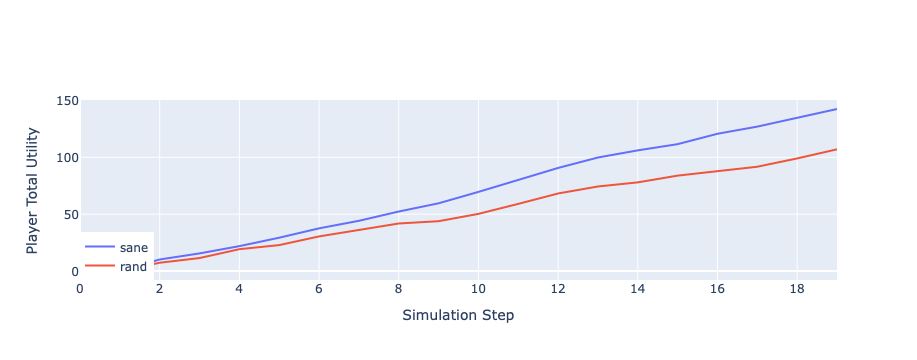
Better.